掌握Apache Spark
简介
Apache Spark介绍
Spark SQL
Spark SQL — 大规模结构化数据查询工具
SparkSession — Spark SQL的入口
Builder — 创建SparkSession的流畅API
Datasets — 支持编译期类型检查
Encoders — Internal Row Converters
InternalRow — Internal Binary Row Format
DataFrame — Dataset of Rows
Row
RowEncoder — DataFrame Encoder
Schema — Structure of Data
StructType
StructField
Data Types
Dataset Operators
Column Operators
Standard Functions — functions object
User-Defined Functions (UDFs)
Aggregation — Typed and Untyped Grouping
UserDefinedAggregateFunction — User-Defined Aggregate Functions (UDAFs)
Window Aggregate Operators — Windows
Joins
Caching
DataSource API — Loading and Saving Datasets
DataFrameReader — Reading from External Data Sources
DataFrameWriter
DataSource — Pluggable Data Sources
DataSourceRegister
CSVFileFormat
ParquetFileFormat
Custom Formats
BaseRelation
QueryPlanner — From Logical to Physical Plans
SparkPlanner — Default Query Planner (with no Hive Support)
BasicOperators
DataSourceStrategy
DDLStrategy
FileSourceStrategy
JoinSelection
Structured Query Plan
Query Execution
EnsureRequirements Physical Plan Optimization
LogicalPlan — Logical Query Plan
AlterViewAsCommand Runnable Command
ClearCacheCommand Runnable Command
CreateViewCommand Runnable Command
DeserializeToObject Logical Operator
ExplainCommand Logical Command
InMemoryRelation Logical Operator
Join Logical Operator
LocalRelation Logical Operator
Logical Query Plan Analyzer
CheckAnalysis
SparkPlan — Physical Execution Plan
BroadcastHashJoinExec Physical Operator
BroadcastNestedLoopJoinExec Physical Operator
CoalesceExec Physical Operator
ExecutedCommandExec Physical Operator
InMemoryTableScanExec Physical Operator
LocalTableScanExec Physical Operator
ShuffleExchange Physical Operator
WindowExec Physical Operator
ExchangeCoordinator and Adaptive Query Execution
ShuffledRowRDD
Debugging Query Execution
Datasets vs DataFrames vs RDDs
SQLConf
Catalog
ExternalCatalog — System Catalog of Permanent Entities
SessionState
SessionCatalog
SQL Parser Framework
SparkSqlAstBuilder
SQLExecution Helper Object
Logical Query Plan Optimizer
Predicate Pushdown / Filter Pushdown
Combine Typed Filters
Propagate Empty Relation
Simplify Casts
Column Pruning
Constant Folding
Nullability (NULL Value) Propagation
Vectorized Parquet Decoder
GetCurrentDatabase / ComputeCurrentTime
Eliminate Serialization
CatalystSerde
Tungsten Execution Backend (aka Project Tungsten)
Whole-Stage Code Generation (CodeGen)
Hive Integration
Spark SQL CLI - spark-sql
DataSinks Strategy
CacheManager — In-Memory Cache for Cached Tables
Thrift JDBC/ODBC Server — Spark Thrift Server (STS)
SparkSQLEnv
Catalyst — Tree Manipulation Framework
TreeNode
Expression TreeNode
Attribute Expression
Generator
(obsolete) SQLContext
Settings
Spark MLlib
Spark MLlib — Machine Learning in Spark
ML Pipelines and PipelineStages (spark.ml)
ML Pipeline Components — Transformers
Tokenizer
ML Pipeline Components — Estimators
ML Pipeline Models
Evaluators
CrossValidator
Params and ParamMaps
ML Persistence — Saving and Loading Models and Pipelines
Example — Text Classification
Example — Linear Regression
Latent Dirichlet Allocation (LDA)
Vector
LabeledPoint
Streaming MLlib
GeneralizedLinearRegression
Structured Streaming
Structured Streaming — Streaming Datasets
DataStreamReader
DataStreamWriter
Streaming Sources
FileStreamSource
KafkaSource
MemoryStream
TextSocketSource
Streaming Sinks
ConsoleSink
ForeachSink
StreamSourceProvider — Streaming Source Provider
KafkaSourceProvider
TextSocketSourceProvider
StreamSinkProvider
StreamingQueryManager
StreamingQuery
Trigger
StreamExecution
StreamingRelation
StreamingQueryListenerBus
MemoryPlan Logical Query Plan
Spark Streaming
Spark Streaming
StreamingContext
Stream Operators
Windowed Operators
SaveAs Operators
Stateful Operators
PairDStreamFunctions
web UI and Streaming Statistics Page
Streaming Listeners
Checkpointing
JobScheduler
InputInfoTracker
JobGenerator
DStreamGraph
Discretized Streams (DStreams)
Input DStreams
ReceiverInputDStreams
ConstantInputDStreams
ForEachDStreams
WindowedDStreams
MapWithStateDStreams
StateDStreams
TransformedDStream
Receivers
ReceiverTracker
ReceiverSupervisors
ReceivedBlockHandlers
Ingesting Data from Kafka
KafkaUtils — Creating Kafka DStreams and RDDs
DirectKafkaInputDStream — Direct Kafka DStream
ConsumerStrategy — Kafka Consumers' Post-Configuration API
ConsumerStrategies Factory Object
LocationStrategy — Preferred Hosts per Topic Partitions
KafkaRDD
HasOffsetRanges and OffsetRange
RecurringTimer
Backpressure
Dynamic Allocation (Elastic Scaling)
ExecutorAllocationManager
StreamingSource
Settings
Spark Core / Tools
Spark Shell — spark-shell shell script
Web UI — Spark Application’s Web Console
Jobs Tab
Stages Tab
Stages for All Jobs
Stage Details
Pool Details
Storage Tab
BlockStatusListener Spark Listener
Environment Tab
EnvironmentListener Spark Listener
Executors Tab
ExecutorsListener Spark Listener
SQL Tab
SQLListener Spark Listener
JobProgressListener Spark Listener
StorageStatusListener Spark Listener
StorageListener Spark Listener
RDDOperationGraphListener Spark Listener
SparkUI
Spark Submit — spark-submit shell script
SparkSubmitArguments
SparkSubmitOptionParser — spark-submit's Command-Line Parser
SparkSubmitCommandBuilder Command Builder
spark-class shell script
AbstractCommandBuilder
SparkLauncher — Launching Spark Applications Programmatically
Spark Core / Architecture
Spark Architecture
Driver
Executors
TaskRunner
ExecutorSource
Master
Workers
Spark Core / RDD
Anatomy of Spark Application
SparkConf — Programmable Configuration for Spark Applications
Spark Properties and spark-defaults.conf Properties File
Deploy Mode
SparkContext
HeartbeatReceiver RPC Endpoint
Inside Creating SparkContext
ConsoleProgressBar
Local Properties — Creating Logical Job Groups
RDD — Resilient Distributed Dataset
RDD Lineage — Logical Execution Plan
ParallelCollectionRDD
MapPartitionsRDD
OrderedRDDFunctions
CoGroupedRDD
SubtractedRDD
HadoopRDD
ShuffledRDD
BlockRDD
Operators
Transformations
PairRDDFunctions
Actions
Caching and Persistence
StorageLevel
Partitions and Partitioning
Partition
Partitioner
HashPartitioner
Shuffling
Checkpointing
CheckpointRDD
RDD Dependencies
NarrowDependency — Narrow Dependencies
ShuffleDependency — Shuffle Dependencies
Map/Reduce-side Aggregator
Spark Core / Optimizations
Broadcast variables
Accumulators
Spark Core / Services
SerializerManager
MemoryManager — Memory Management
UnifiedMemoryManager
SparkEnv — Spark Runtime Environment
DAGScheduler — Stage-Oriented Scheduler
Jobs
Stage — Physical Unit Of Execution
ShuffleMapStage — Intermediate Stage in Execution DAG
ResultStage — Final Stage in Job
DAGScheduler Event Bus
JobListener
JobWaiter
Task Scheduler
Tasks
ShuffleMapTask — Task for ShuffleMapStage
ResultTask
TaskDescription
FetchFailedException
MapStatus — Shuffle Map Output Status
TaskSet — Set of Tasks for Stage
Schedulable
TaskSetManager
Schedulable Pool
Schedulable Builders
FIFOSchedulableBuilder
FairSchedulableBuilder
Scheduling Mode — spark.scheduler.mode Spark Property
TaskSchedulerImpl — Default TaskScheduler
Speculative Execution of Tasks
TaskResultGetter
TaskContext
TaskContextImpl
TaskResults — DirectTaskResult and IndirectTaskResult
TaskMemoryManager
MemoryConsumer
TaskMetrics
ShuffleWriteMetrics
TaskSetBlacklist — Blacklisting Executors and Nodes For TaskSet
SchedulerBackend — Pluggable Scheduler Backends
CoarseGrainedSchedulerBackend
DriverEndpoint — CoarseGrainedSchedulerBackend RPC Endpoint
ExecutorBackend — Pluggable Executor Backends
CoarseGrainedExecutorBackend
MesosExecutorBackend
BlockManager — Key-Value Store for Blocks
MemoryStore
DiskStore
BlockDataManager
ShuffleClient
BlockTransferService — Pluggable Block Transfers
NettyBlockTransferService — Netty-Based BlockTransferService
NettyBlockRpcServer
BlockManagerMaster — BlockManager for Driver
BlockManagerMasterEndpoint — BlockManagerMaster RPC Endpoint
DiskBlockManager
BlockInfoManager
BlockInfo
BlockManagerSlaveEndpoint
DiskBlockObjectWriter
MapOutputTracker — Shuffle Map Output Registry
MapOutputTrackerMaster — MapOutputTracker For Driver
MapOutputTrackerMasterEndpoint
MapOutputTrackerWorker — MapOutputTracker for Executors
ShuffleManager — Pluggable Shuffle Systems
SortShuffleManager — The Default Shuffle System
ExternalShuffleService
OneForOneStreamManager
ShuffleBlockResolver
IndexShuffleBlockResolver
ShuffleWriter
BypassMergeSortShuffleWriter
SortShuffleWriter
UnsafeShuffleWriter — ShuffleWriter for SerializedShuffleHandle
BaseShuffleHandle — Fallback Shuffle Handle
BypassMergeSortShuffleHandle — Marker Interface for Bypass Merge Sort Shuffle Handles
SerializedShuffleHandle — Marker Interface for Serialized Shuffle Handles
ShuffleReader
BlockStoreShuffleReader
ShuffleBlockFetcherIterator
ShuffleExternalSorter — Cache-Efficient Sorter
ExternalSorter
Serialization
Serializer — Task SerDe
SerializerInstance
SerializationStream
DeserializationStream
ExternalClusterManager — Pluggable Cluster Managers
BroadcastManager
BroadcastFactory — Pluggable Broadcast Variable Factories
TorrentBroadcastFactory
TorrentBroadcast
CompressionCodec
ContextCleaner — Spark Application Garbage Collector
CleanerListener
Dynamic Allocation (of Executors)
ExecutorAllocationManager — Allocation Manager for Spark Core
ExecutorAllocationClient
ExecutorAllocationListener
ExecutorAllocationManagerSource
HTTP File Server
Data Locality
Cache Manager
OutputCommitCoordinator
RpcEnv — RPC Environment
RpcEndpoint
RpcEndpointRef
RpcEnvFactory
Netty-based RpcEnv
TransportConf — Transport Configuration
Spark Deployment Environments
Deployment Environments — Run Modes
Spark local (pseudo-cluster)
LocalSchedulerBackend
LocalEndpoint
Spark on cluster
Spark on YARN
Spark on YARN
YarnShuffleService — ExternalShuffleService on YARN
ExecutorRunnable
Client
YarnRMClient
ApplicationMaster
AMEndpoint — ApplicationMaster RPC Endpoint
YarnClusterManager — ExternalClusterManager for YARN
TaskSchedulers for YARN
YarnScheduler
YarnClusterScheduler
SchedulerBackends for YARN
YarnSchedulerBackend
YarnClientSchedulerBackend
YarnClusterSchedulerBackend
YarnSchedulerEndpoint RPC Endpoint
YarnAllocator
Introduction to Hadoop YARN
Setting up YARN Cluster
Kerberos
ConfigurableCredentialManager
ClientDistributedCacheManager
YarnSparkHadoopUtil
Settings
Spark Standalone
Spark Standalone
Standalone Master
Standalone Worker
web UI
Submission Gateways
Management Scripts for Standalone Master
Management Scripts for Standalone Workers
Checking Status
Example 2-workers-on-1-node Standalone Cluster (one executor per worker)
StandaloneSchedulerBackend
Spark on Mesos
Spark on Mesos
MesosCoarseGrainedSchedulerBackend
About Mesos
Execution Model
Execution Model
Security
Spark Security
Securing Web UI
Spark Core / Data Sources
Data Sources in Spark
Using Input and Output (I/O)
Parquet
Spark and Cassandra
Spark and Kafka
Couchbase Spark Connector
Spark GraphX
Spark GraphX — Distributed Graph Computations
Graph Algorithms
Monitoring, Tuning and Debugging
Unified Memory Management
Spark History Server
HistoryServer
SQLHistoryListener
FsHistoryProvider
HistoryServerArguments
Logging
Performance Tuning
Spark Metrics System
MetricsConfig — Metrics System Configuration
Metrics Source
SparkListener — Intercepting Events from Spark Scheduler
LiveListenerBus
ReplayListenerBus
SparkListenerBus — Internal Contract for Spark Event Buses
EventLoggingListener — Event Logging
StatsReportListener — Logging Summary Statistics
JsonProtocol
Debugging Spark using sbt
Varia
Building Apache Spark from Sources
Spark and Hadoop
SparkHadoopUtil
Spark and software in-memory file systems
Spark and The Others
Distributed Deep Learning on Spark
Spark Packages
Interactive Notebooks
Interactive Notebooks
Apache Zeppelin
Spark Notebook
Spark Tips and Tricks
Spark Tips and Tricks
Access private members in Scala in Spark shell
SparkException: Task not serializable
Running Spark Applications on Windows
Exercises
One-liners using PairRDDFunctions
Learning Jobs and Partitions Using take Action
Spark Standalone - Using ZooKeeper for High-Availability of Master
Spark’s Hello World using Spark shell and Scala
WordCount using Spark shell
Your first complete Spark application (using Scala and sbt)
Spark (notable) use cases
Using Spark SQL to update data in Hive using ORC files
Developing Custom SparkListener to monitor DAGScheduler in Scala
Developing RPC Environment
Developing Custom RDD
Working with Datasets using JDBC (and PostgreSQL)
Causing Stage to Fail
Further Learning
Courses
Books
Spark Distributions
DataStax Enterprise
MapR Sandbox for Hadoop (Spark 1.5.2 only)
Spark Workshop
Spark Advanced Workshop
Requirements
Day 1
Day 2
Spark Talk Ideas
Spark Talks Ideas (STI)
10 Lesser-Known Tidbits about Spark Standalone
Learning Spark internals using groupBy (to cause shuffle)
Powered by
GitBook
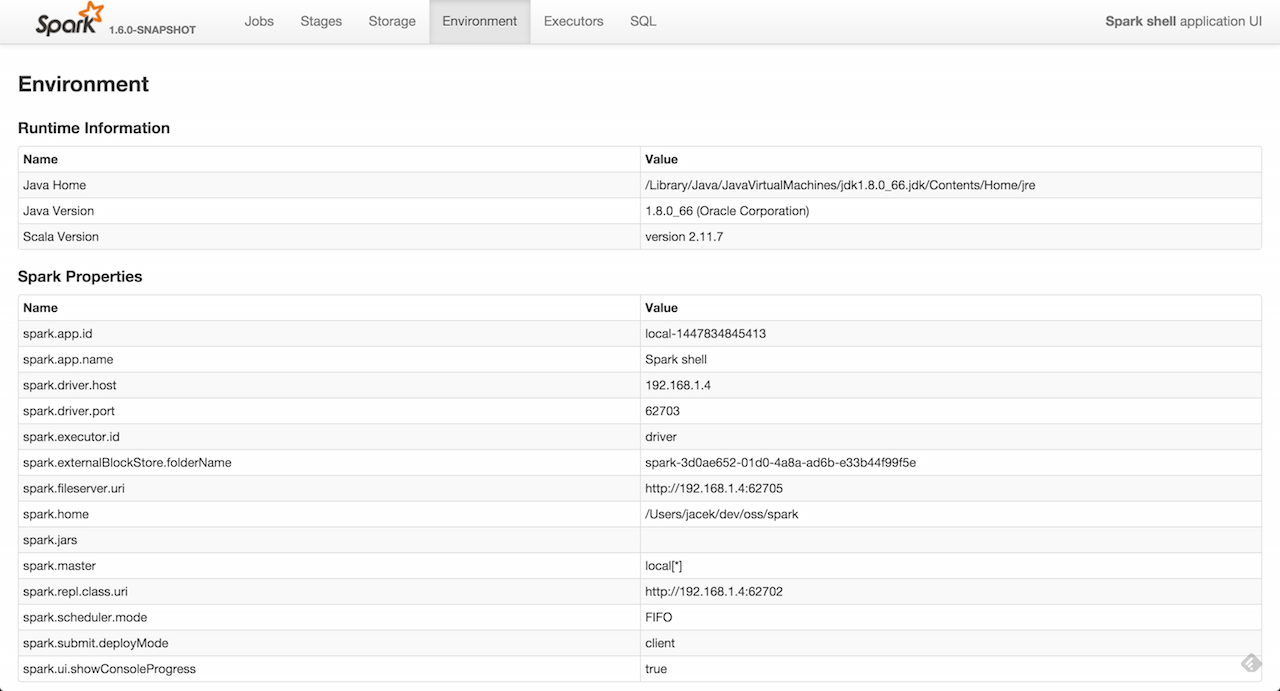
Environment Tab
Environment Tab
Figure 1. Environment tab in Web UI
results matching "
"
No results matching "
"