import org.apache.spark._
scala> SparkEnv.get
res0: org.apache.spark.SparkEnv = org.apache.spark.SparkEnv@49322d04SparkEnv — Spark Runtime Environment
Spark Runtime Environment (SparkEnv) is the runtime environment with Spark’s public services that interact with each other to establish a distributed computing platform for a Spark application.
Spark Runtime Environment is represented by a SparkEnv object that holds all the required runtime services for a running Spark application with separate environments for the driver and executors.
The idiomatic way in Spark to access the current SparkEnv when on the driver or executors is to use get method.
| Property | Service | Description |
|---|---|---|
Serializer |
||
SerializerManager |
||
BroadcastManager |
||
securityManager |
SecurityManager |
|
MetricsSystem |
||
outputCommitCoordinator |
OutputCommitCoordinator |
| Name | Initial Value | Description |
|---|---|---|
Disabled, i.e. |
Used to mark |
|
|
Tip
|
Enable Add the following line to Refer to Logging. |
Creating "Base" SparkEnv — create Method
create(
conf: SparkConf,
executorId: String,
hostname: String,
port: Int,
isDriver: Boolean,
isLocal: Boolean,
numUsableCores: Int,
listenerBus: LiveListenerBus = null,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnvcreate is a internal helper method to create a "base" SparkEnv regardless of the target environment, i.e. a driver or an executor.
| Input Argument | Usage |
|---|---|
|
Used to create RpcEnv and NettyBlockTransferService. |
|
Used to create RpcEnv and NettyBlockTransferService. |
|
Used to create MemoryManager, NettyBlockTransferService and BlockManager. |
When executed, create creates a Serializer (based on spark.serializer setting). You should see the following DEBUG message in the logs:
DEBUG SparkEnv: Using serializer: [serializer]It creates another Serializer (based on spark.closure.serializer).
It creates a ShuffleManager based on spark.shuffle.manager Spark property.
It creates a MemoryManager based on spark.memory.useLegacyMode setting (with UnifiedMemoryManager being the default and numCores the input numUsableCores).
create creates a NettyBlockTransferService. It uses spark.driver.blockManager.port for the port on the driver and spark.blockManager.port for the port on executors.
|
Caution
|
FIXME A picture with SparkEnv, NettyBlockTransferService and the ports "armed".
|
create creates a BlockManagerMaster object with the BlockManagerMaster RPC endpoint reference (by registering or looking it up by name and BlockManagerMasterEndpoint), the input SparkConf, and the input isDriver flag.
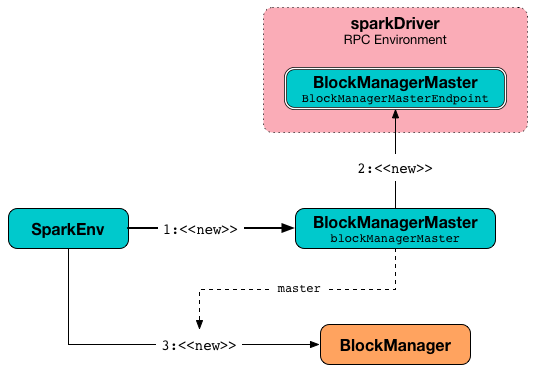
Figure 1. Creating BlockManager for the Driver
|
Note
|
create registers the BlockManagerMaster RPC endpoint for the driver and looks it up for executors.
|

Figure 2. Creating BlockManager for Executor
It creates a BlockManager (using the above BlockManagerMaster, NettyBlockTransferService and other services).
create creates a BroadcastManager.
create creates a MapOutputTrackerMaster or MapOutputTrackerWorker for the driver and executors, respectively.
|
Note
|
The choice of the real implementation of MapOutputTracker is based on whether the input executorId is driver or not.
|
create registers or looks up RpcEndpoint as MapOutputTracker. It registers MapOutputTrackerMasterEndpoint on the driver and creates a RPC endpoint reference on executors. The RPC endpoint reference gets assigned as the MapOutputTracker RPC endpoint.
|
Caution
|
FIXME |
It creates a CacheManager.
It creates a MetricsSystem for a driver and a worker separately.
It initializes userFiles temporary directory used for downloading dependencies for a driver while this is the executor’s current working directory for an executor.
An OutputCommitCoordinator is created.
|
Note
|
create is called by createDriverEnv and createExecutorEnv.
|
Registering or Looking up RPC Endpoint by Name — registerOrLookupEndpoint Method
registerOrLookupEndpoint(name: String, endpointCreator: => RpcEndpoint)registerOrLookupEndpoint registers or looks up a RPC endpoint by name.
If called from the driver, you should see the following INFO message in the logs:
INFO SparkEnv: Registering [name]And the RPC endpoint is registered in the RPC environment.
Otherwise, it obtains a RPC endpoint reference by name.
Creating SparkEnv for Driver — createDriverEnv Method
createDriverEnv(
conf: SparkConf,
isLocal: Boolean,
listenerBus: LiveListenerBus,
numCores: Int,
mockOutputCommitCoordinator: Option[OutputCommitCoordinator] = None): SparkEnvcreateDriverEnv creates a SparkEnv execution environment for the driver.
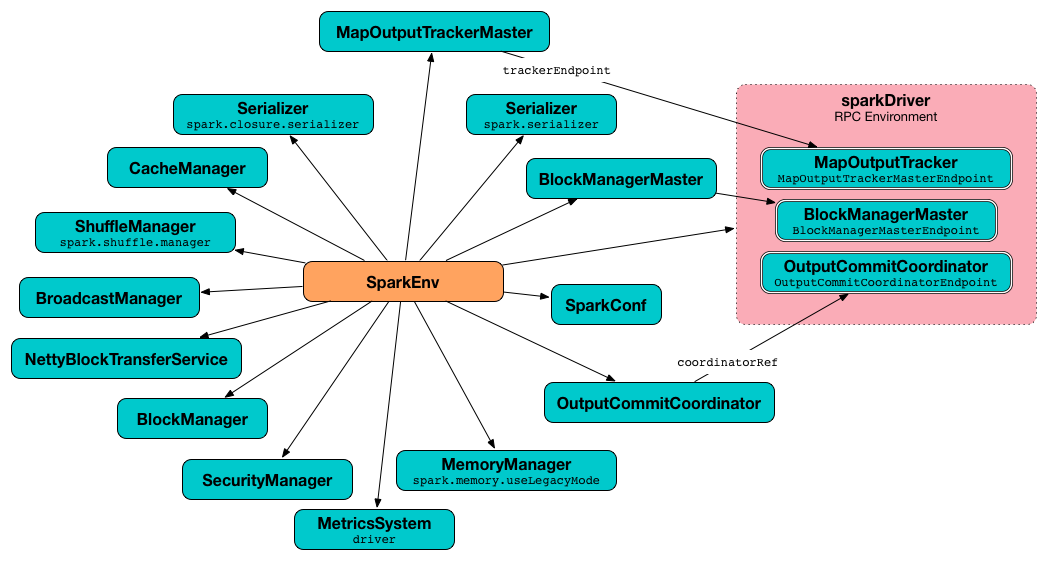
Figure 3. Spark Environment for driver
createDriverEnv accepts an instance of SparkConf, whether it runs in local mode or not, LiveListenerBus, the number of cores to use for execution in local mode or 0 otherwise, and a OutputCommitCoordinator (default: none).
createDriverEnv ensures that spark.driver.host and spark.driver.port settings are defined.
It then passes the call straight on to the create helper method (with driver executor id, isDriver enabled, and the input parameters).
|
Note
|
createDriverEnv is exclusively used by SparkContext to create a SparkEnv (while a SparkContext is being created for the driver).
|
Creating SparkEnv for Executor — createExecutorEnv Method
createExecutorEnv(
conf: SparkConf,
executorId: String,
hostname: String,
port: Int,
numCores: Int,
ioEncryptionKey: Option[Array[Byte]],
isLocal: Boolean): SparkEnvcreateExecutorEnv creates an executor’s (execution) environment that is the Spark execution environment for an executor.
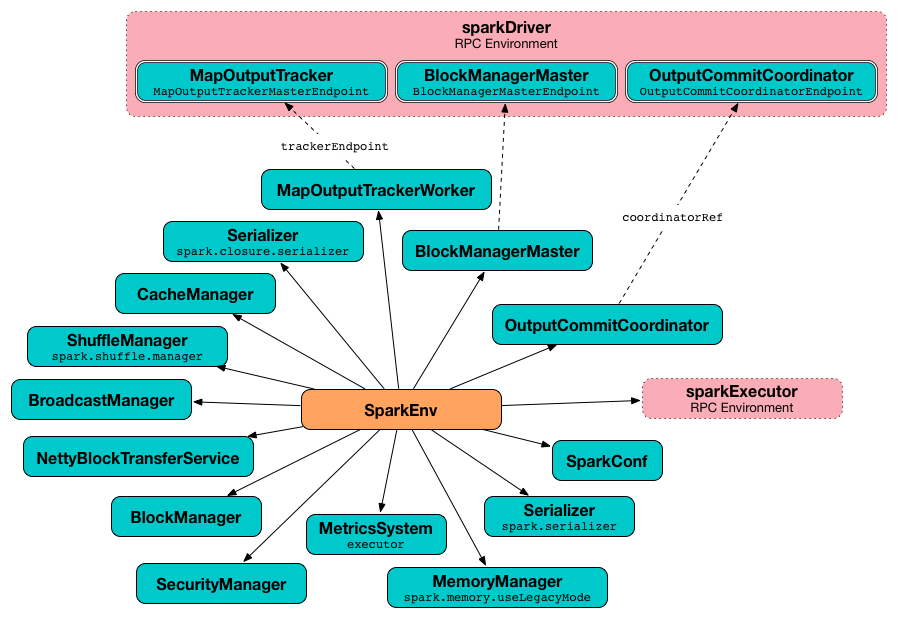
Figure 4. Spark Environment for executor
|
Note
|
createExecutorEnv is a private[spark] method.
|
createExecutorEnv simply creates the base SparkEnv (passing in all the input parameters) and sets it as the current SparkEnv.
|
Note
|
The number of cores numCores is configured using --cores command-line option of CoarseGrainedExecutorBackend and is specific to a cluster manager.
|
|
Note
|
createExecutorEnv is used when CoarseGrainedExecutorBackend runs and MesosExecutorBackend registers a Spark executor.
|
Getting Current SparkEnv — get Method
get: SparkEnvget returns the current SparkEnv.
import org.apache.spark._
scala> SparkEnv.get
res0: org.apache.spark.SparkEnv = org.apache.spark.SparkEnv@49322d04 Stopping SparkEnv — stop Method
stop(): Unitstop checks isStopped internal flag and does nothing when enabled.
|
Note
|
stop is a private[spark] method.
|
Otherwise, stop turns isStopped flag on, stops all pythonWorkers and requests the following services to stop:
Only on the driver, stop deletes the temporary directory. You can see the following WARN message in the logs if the deletion fails.
WARN Exception while deleting Spark temp dir: [path]|
Note
|
stop is used when SparkContext stops (on the driver) and Executor stops.
|
Settings
| Spark Property | Default Value | Description |
|---|---|---|
|
TIP: Enable DEBUG logging level for
|
|
|
||
|
Controls what type of the MemoryManager to use. When enabled (i.e. |