Apache Spark
Apache Spark 是一个优先使用内存的通用开源分布式集群计算框架 可以用它对大量数据做:
-
数据抽取加载(ETL)
-
数据分析(analytics)
-
机器学习 (machine learning)
-
图计算 (graph processing)
支持批处理(batch processing) 和实时处理(streaming processing)
支持多种语言调用: Scala, Python, Java, R, and SQL.
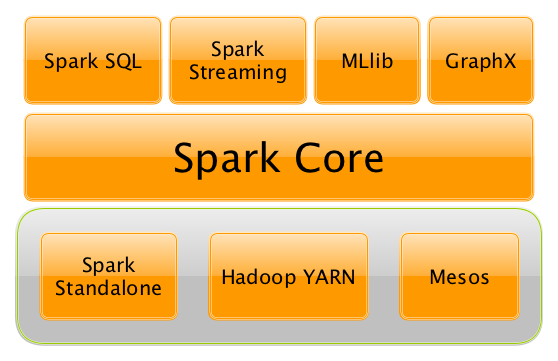
Figure 1. Spark平台
与基于磁盘俩阶段运算的Hadoop MapReduce计算引擎相比,Spark基于内存多阶段运算的数据处理方式通常能提供更高效的性能,如做迭代运算,数据挖掘(read Spark officially sets a new record in large-scale sorting).
Spark关注处理速度, 易用性, 可扩展性 及 交互式分析.
Spark也经常被称为 集群式计算引擎 , 执行引擎.
Spark是一个很适合运行 类似 机器学习算法,即席查询 的复杂多阶段运算任务的分布式计算平台,Spark使用RDD弹性分别式数据集 Resilient Distributed Dataset描述这样的任务 使用Spark可以简化机器学习,预测性分析类应用的开发。
虽然Spark本身主要由http://scala-lang.org/[Scala]编写, 但是也支持Java, Python, and R 调用
|
Note
|
微软的 Mobius 项目 为Spark了提供C#调用支持。 如果典型的MapReduce计算引擎已经不能满足您对数据量和处理时间的要求,你可以考虑试试Spark |
-
没有数据类型限制,不依赖特定的数据源.
-
可以处理巨量的数据.
Apache Spark项目包含以下子项目:
-
SQL (使用Datasets)
-
machine learning (pipelines)
-
graph 他们都构建在Spark Core之上并提供统一的访问方式,你可以把他们当成一个应用
Spark可以运行在你的个人电脑上也可以运行在集群上,可以运行在 Hadoop YARN, Apache Mesos也可以运行在共有云上(Amazon EC2 or IBM Bluemix).
Spark可以访问多种数据源data sources.
Apache Spark的 Streaming 和 SQL 编程模型能够帮助开发人员和数据科学家更容易的创建机器学习和图分析应用
为什么要使用Spark
====易于使用,上手简单
Spark提供了spark-shell 你可以在你的笔记本上用spark-shell快速的编写运行一个spark应用 然后你还可以通过Spark Standalone 提供的集群管理方式发布你的应用
适用场景广
就像Apache Spark的作者Matei Zaharia说的那样 Introduction to AmpLab Spark Internals video:
不单支持类似MapReduce的批处理计算还支持像图计算,集群学习等迭代计算.
不单支持(运行时间)短任务还支持运行时间长的任务
Spark支持批处理,交互式操作,和流计算并提供一套统一的API.
通过Spark Streaming支持近实时数据处理. 通过Spark Shell支持交互式操作
不错的Spark介绍视频: Apache Spark是什么? ==== 从分布式批处理中获益
当提到 分布式比处理 时, 你可能会想到Hadoop.
Spark借鉴了Hadoop MapReduce的设计思想 并能和Hadoop一起使用 在Yarn,HDFS上使用能够提高分布式计算性能并能简化操作.
一句话: Spark就是Hadoop++.
RDD - 分布式并行的Scala集合
如果你是一个Scala开发者,你会发现Spark的API与 Scala的集合API非常相似
统一的开发和部署环境
支持交互式分析 即席查询
支持丰富的数据源
Spark支持从关系数据库,NoSql,文件系统等数据源读取数据.
底层优化
Apache Spark用 有向无环图 描述计算逻辑,在真正用到语句执行结果时才去执行语句 这种行为被称为 懒解析(lazy evaluation)